
在 “Hadoop 是否已失宠?” 的选题调研中,笔者调查了银行、Hadoop 发行商、Hadoop 企业用户以及部分工程师的意见,所处环境、业务需求以及看问题角度的不同让这些组织或个人有着不同的意见。如果你的数据量和增长速度还未达到使用 Hadoop 的级别,你一定会认为 Hadoop 是十分不明智的选择; 相反,当你已经从 Hadoop 生态受益良久时,你一定会认为这是大数据时代最佳解决方案之一,比如那些从 PostgreSQL 迁移至 Hadoop 的企业。

很多人不屑于讨论 Hadoop 与 Spark、Flink 等之间的对比,因为在大多数人的认知中,只要提起 Hadoop 就一定代表着整个 Hadoop 生态。但在不少企业内部,Hadoop 更多的时候只是表示狭义上的 MapReduce 和 HDFS,由于大多数企业内部还保留着关系型数据库时代的解决方案,因此企业更倾向于将狭义上的 Hadoop 和其他方案与业务需求对比,选择最合适的搭建模式,尤其是资金不太充足的企业,搭建整个 Hadoop 生态的前期和后期维护成本以及复杂性是非常高的,其中有些问题可能传统方案也足以解决。
如今,不少企业将数据库从 PostgreSQL 迁移到 Hadoop,可能速度、容量以及类型是他们面临的主要问题,PostgreSQL 正在渐渐从这些企业的数据中心消失,并且在行业中,Hadoop 生态各开源工具的使用频率很可能远远超过 PostgreSQL。与此同时,也会有一些企业从 Hadoop 迁移至 PostgreSQL,这为思考大数据问题和解决方案及其影响提供了机会。
很早之前,我们在分析大数据问题时倾向于三个层面: 管理不断增加的数据量、管理数据增长速度以及处理多种类的数据结构。值得注意的是,这些只是问题类型,而不是问题本身,同类别的问题之间可能存在很大差异,所有解决方案几乎都意味着不小的成本付出,我经常看到将 Hadoop 作为企业通用解决方案,而不关注成本和问题类型的,结果往往是整个体系过于复杂,难以维护,速度可能很慢。
因此,我们应该学会区分 Hadoop(狭义的 MR 和 HDFS 组合,不代指整个生态)、Storm 以及 PostgreSQL,Hadoop 是专业通用的解决方案,而 OLTP 和关系型数据库则是更通用的方案。通常,明智的企业会从通用解决方案开始逐渐转向专业解决方案,并且知道应该使用专业的解决方案来解决哪些问题,比如 Hadoop 在批处理方面很牛,但它并不是一个很好的通用 ETL 平台.....
PostgreSQL 与 Hadoop 对比
企业应该清楚,构建 Hadoop 是为了同时解决大数据 3V 问题,这就意味着,如果你只存在某一方面的困扰,那么构建 Hadoop 的成本就显得过高了。PostgreSQL 和其他关系型数据解决方案为数据提供了非常好的保证,因为它们强化了多样性,在写入时强制使用模式,如果违反该模式,则会引发错误。Hadoop 在读取时强制执行模式,因此可以在存储数据后再尝试读取数据,这对于大量非结构化数据很有帮助。
如果仅仅面临容量和速度问题,首先要查看的解决方案应该是 Postgres-XL 或者类似的集群解决方案,但这些方案确实需要良好的数据分区标准。如果数据集高度相关,这可能不是一个好的解决方案,因为跨节点连接是昂贵的。此外,这些方案也不适用于小型数据集,因为搭建这些解决方案的复杂性和成本也不是很低。
Storm 与 Hadoop 对比
Storm 和 Hadoop 的主攻方向完全不同,Storm 的主工程师 Nathan Marz 曾表示, Storm 可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm 之于实时处理就好比 Hadoop 之于批处理。如果习惯于用 Hadoop 代指整个 Hadoop 生态,那你可能会把 Storm 也划分在生态圈之中。但在企业选择解决方案时,还是应该将狭义上的 Hadoop 与 Storm 进行一些对比。
根据 Hadoop 官网的说法,“Apache Hadoop 是一个框架,允许使用简单的编程模型在整个计算机集群上分布式处理大型数据集,它可以从单个服务器扩展到数千台机器,本地计算和存储,而不是依靠硬件来提供高可用性,该框架本身旨在检测和处理应用层的故障,最大的优势是批处理。
Apache Storm 是一个分布式实时计算系统,本身不会在典型的 Hadoop 集群上运行,可以与任何编程语言一起工作。Storm 是一个任务并行连续计算引擎,使用 Apache ZooKeeper 和主 / 从工作进程,协调拓扑,主机和工作者状态,保证信息语义。无论如何,Storm 必定还是可以从 HDFS 文件消费或者从文件写入到 HDFS 的,Storm 可以与任何队列或数据库系统 (即 RDBMS,NOSQL) 集成。
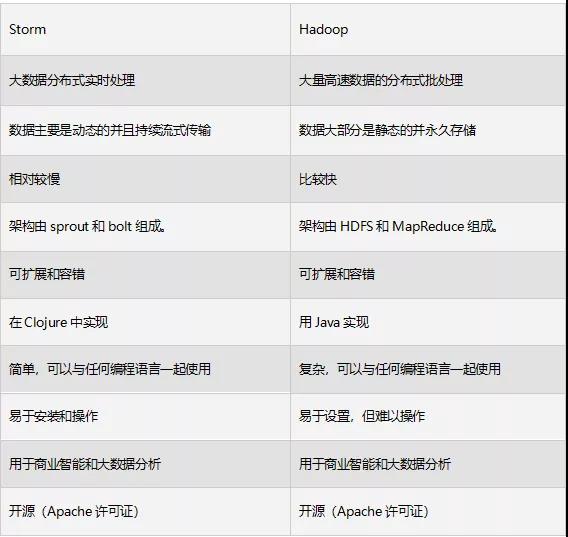
根据官网介绍,Storm 的应用非常广泛,比如实时分析、在线机器学习、连续计算、分布式 RPC、ETL 等。Storm 的速度很快—每个节点每秒钟可处理超过一百万个元组,具有可扩展性和容错性,可确保数据得到处理并且易于设置和操作。在消耗资源相同的情况下,一般来说 Storm 的延时低于 MapReduce,但是吞吐也低于 MapReduce。Storm 是典型的流计算系统,MapReduce 是典型的批处理系统。下表对比了 Storm 和 Hadoop 进行数据处理时的各项指标:
如果你正在因为大数据的 3V 问题烦恼,Hadoop 是最理想的解决方案,如果你只需要解决其中之一,你可以尝试一些其他解决方案,因为此时搭建 Hadoop 生态的性价比会大打折扣。如果数据量较少,比如国外企业的数据量整体上少于国内,没必要使用 Hadoop 处理,因为无法发挥出 Hadoop 的全部价值。






